HW2
TM textbook, Pg. 77 - 3.2 Consider the following set of training examples:
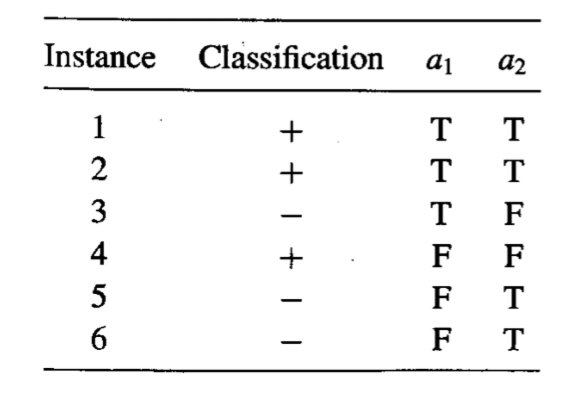
(a) What is the entropy of this collection of training examples with respect to the target function classification?
(b) What is the information gain of a2 relative to these training examples?
3.4 ID3 searches for just one consistent hypothesis, whereas the CANDIDATE- ELIMINATION algorithm finds all consistent hypotheses. Consider the correspondence between these two learning algorithms.
(a) Show the decision tree that would be learned by ID3 assuming it is given the four training examples for the Enjoy Sport? target concept shown in Table 2.1 of Chapter 2.
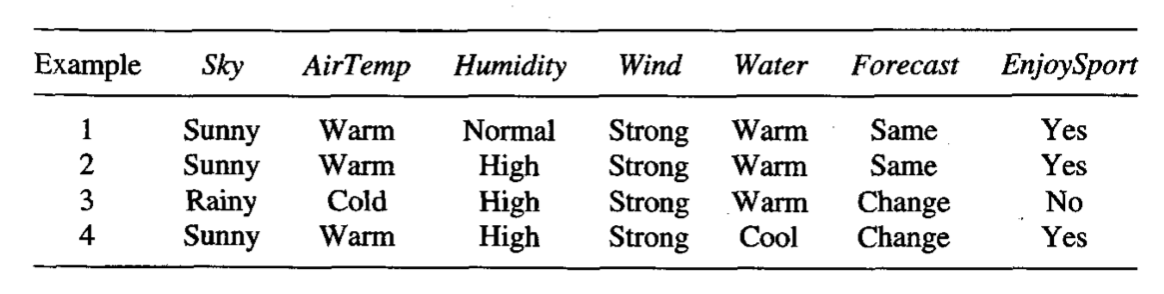
(b) What is the relationship between the learned decision tree and the version space (shown below and in Figure 2.3 of Chapter 2) that is learned from these same examples? Is the learned tree equivalent to one of the members of the version space?
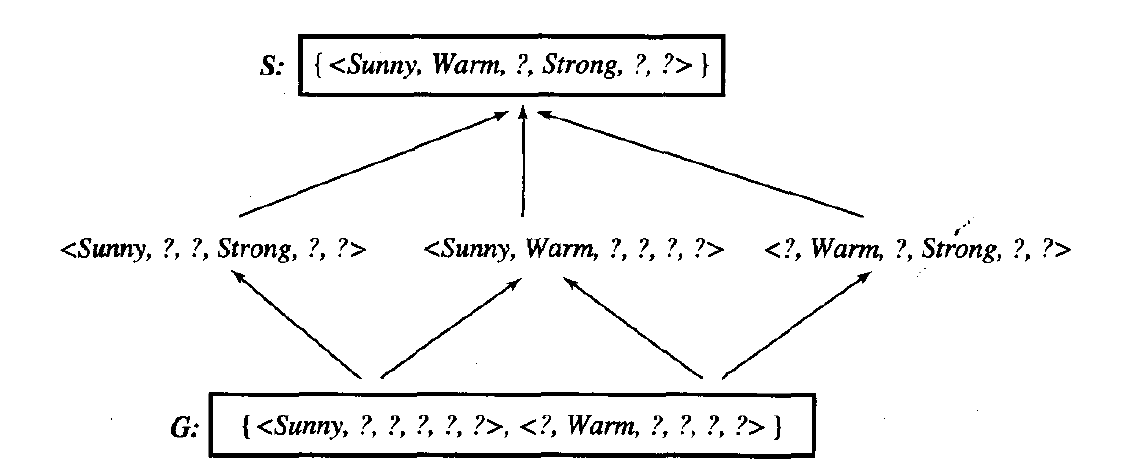
(c) Add the following training example, and compute the new decision tree. This time, show the value of the information gain for each candidate attribute at each step in growing the tree.
Sky Air-Temp Humidity Wind Water Forecast Enjoy-Sport: < Sunny Warm Normal Weak Warm Same No>
Hints:
1) Use DataSpell to do calculations like log or divisions, or even for computing entropy, etc. For example, the code below computes and prints out the entropy for a dataset with two classes, each class consisting of half of the examples; hence the code will compute entropy as 1.
import numpy as np
import scipy
dataset_perc = mp.array([1/2, 1/2]) # we have 50% of data in each of the two classes
dataset_entropy = scipy.stats.entropy(dataset_perc, base = 2) # we use log with base 2
print(dataset_entropy) # this prints 1
2) For 3.4 part c: if more than one attibute gives the same maximum info gain for the root node, select Sky as the root. After deriving the decision tree write down the rule(s) it generates.